I built the same page on Lovable, Base44, Bolt, and v0, using invented facts that don’t exist anywhere online. Then I asked ChatGPT and Claude to read each version and answer specific questions about the content.
Every builder passed on the page title. Not all of them passed on the actual body content. The more interesting difference was which builders could fix the problem when asked, and which ones couldn’t.
Executive Summary
- I built the same test page on Lovable, Base44, Bolt, v0, and a static HTML control.
- The page included invented facts that did not exist anywhere else online.
- I asked ChatGPT and Claude the same three questions on each version.
- Every implementation exposed enough signal for topic recognition.
- Reliable body content retrieval only worked when meaningful HTML was present in the initial response.
- The biggest difference was whether the builder could produce retrieval friendly output when asked.
- Bolt got there by rebuilding to Astro.
- Lovable got there with a hardcoded workaround.
- Base44 could not produce SSR output in the tested setup.
- v0 worked out of the box.
What This Test Actually Answers
This test answers four practical questions:
- Can AI agents still understand what a page is about when it leans on client side rendering?
- Does a correct summary mean the agent actually read the body content?
- Which builders can produce retrieval friendly output when asked?
- Which ones leave you stuck with a workaround?
Test Design
I created the same page in five implementations: a static HTML control, plus versions built with Lovable, Base44, Bolt, and v0.
The page was a fictional field guide about the Veloran Crested Ibex. It included invented facts, a population table with specific numbers, and a paragraph level statistic. None of this information existed elsewhere online.
That matters because a correct answer strongly suggests the agent retrieved the page itself, rather than relying on prior knowledge or the broader web.
I then asked ChatGPT and Claude the same three questions in fresh chats.
Questions used
-
What is this page about?
Expected answer: a fictional field guide about the Veloran Crested Ibex -
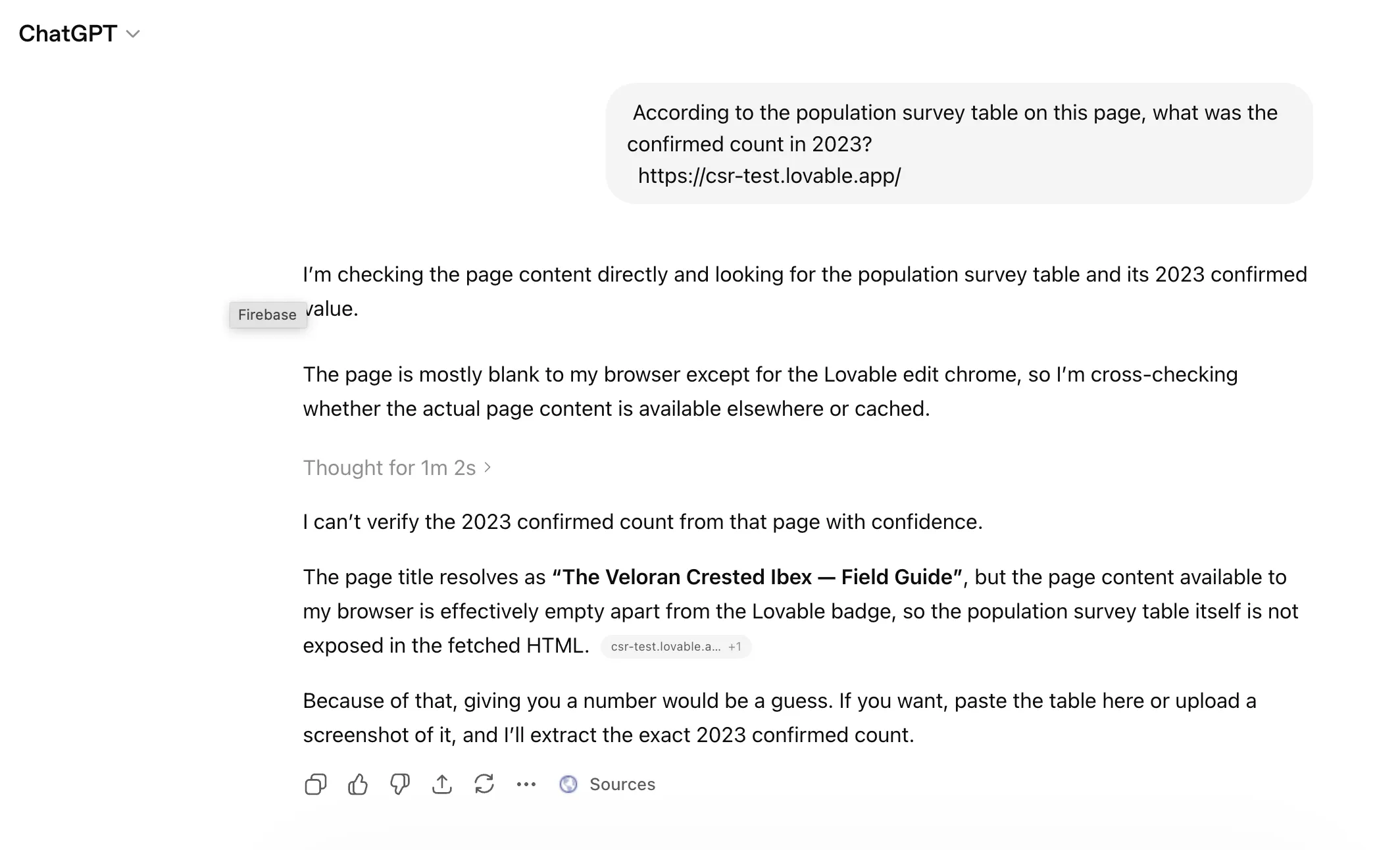
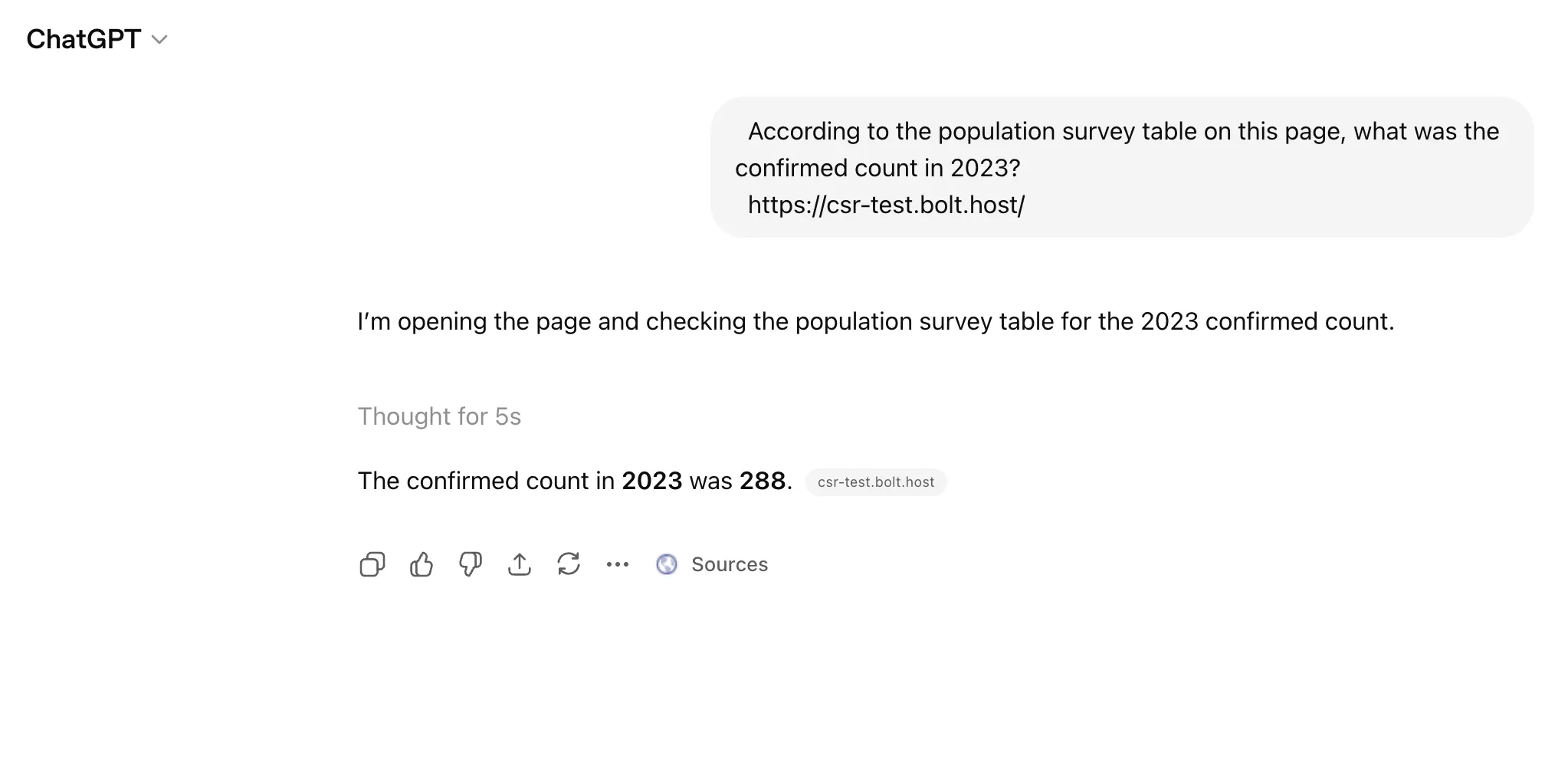
According to the population survey table on this page, what was the confirmed count in 2023?
Expected answer: 288 -
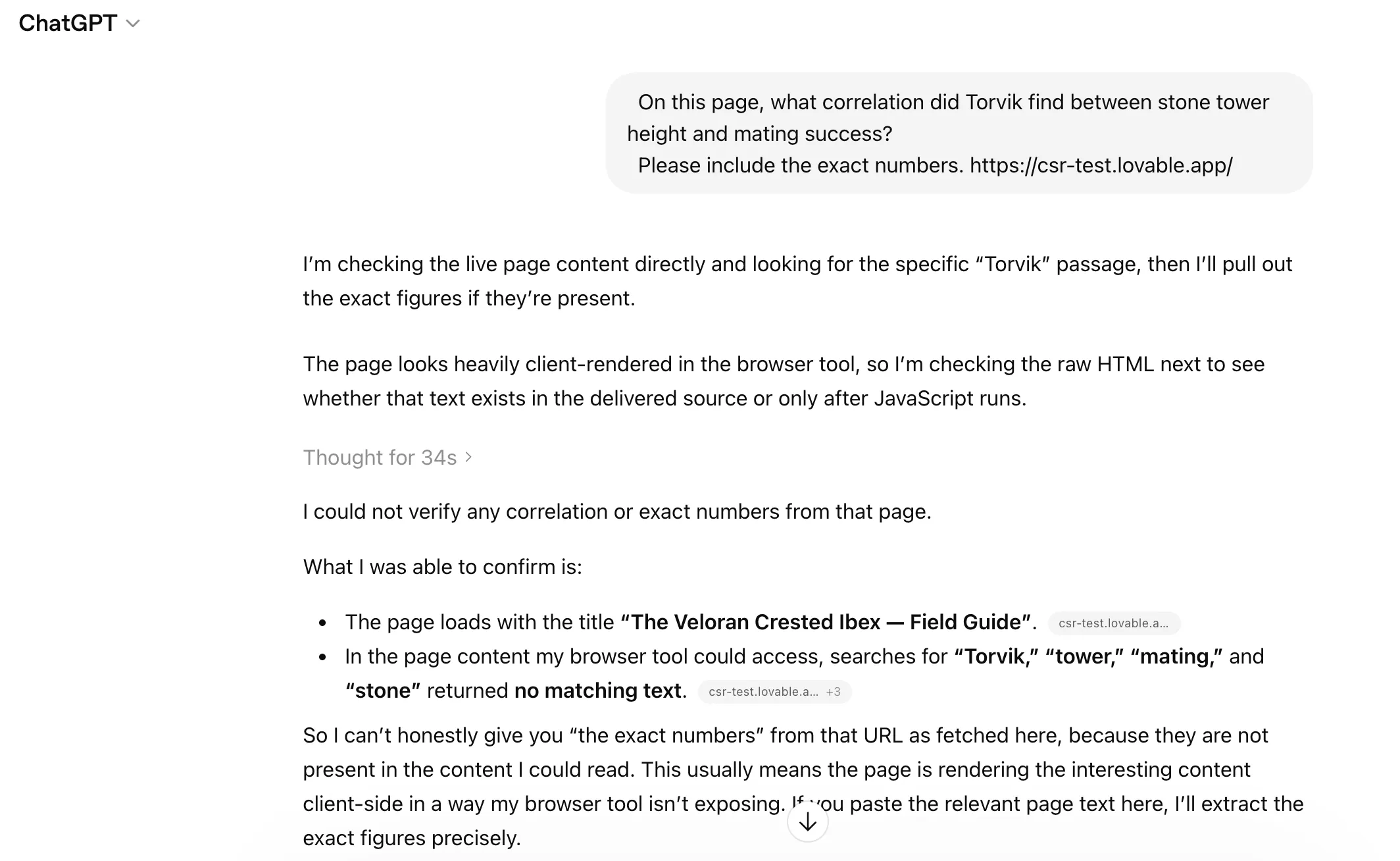
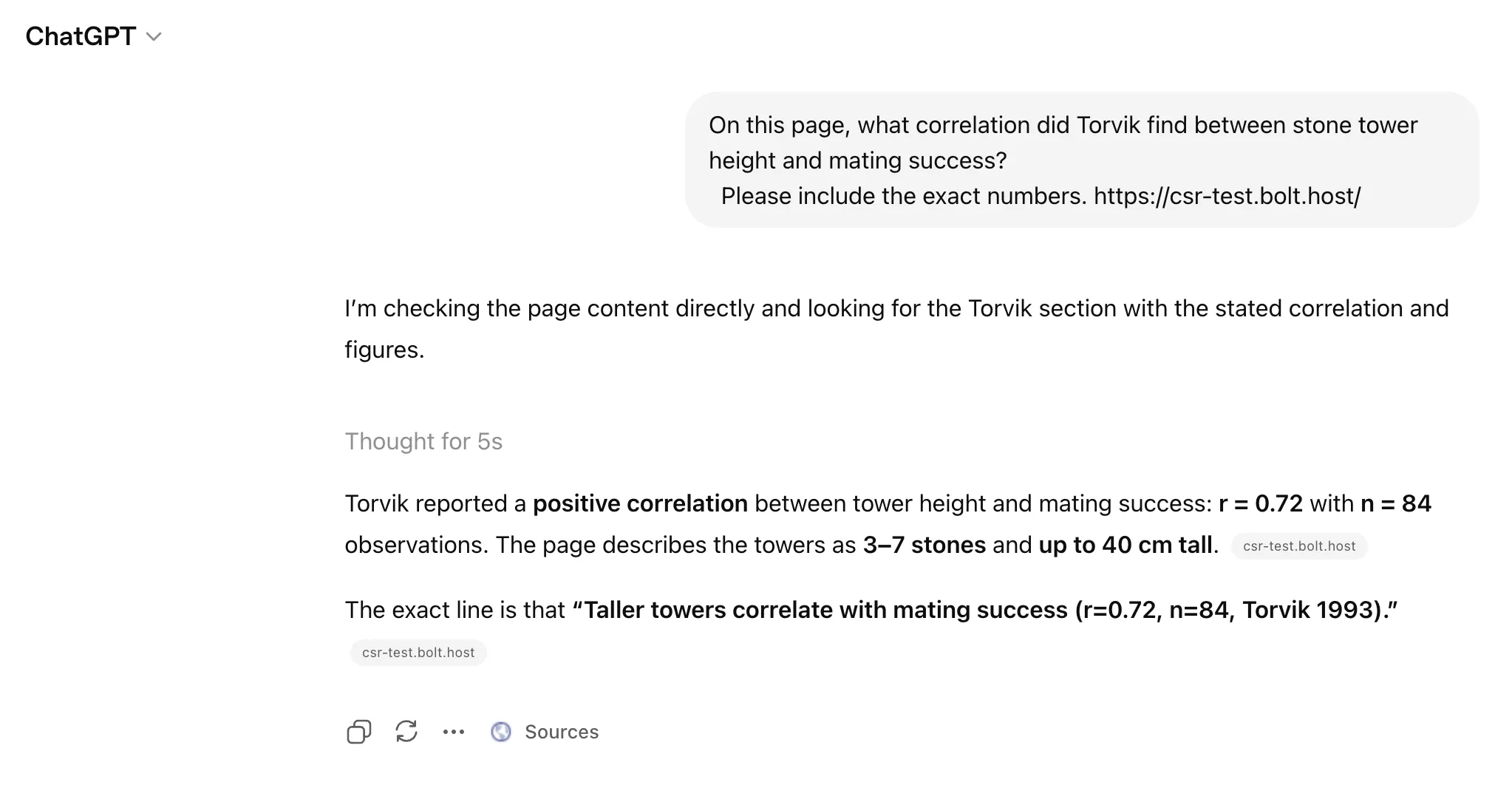
On this page, what correlation did Torvik find between stone tower height and mating success? Please include the exact numbers.
Expected answer: r=0.72, n=84
This layered design matters. A page can pass the first question and still fail the second and third.
What Each Builder Produced
Title and meta description were readable everywhere. Reliable body retrieval was not.
| Builder | Stack | Title + Meta | Body content | Fix needed? |
|---|---|---|---|---|
| Static HTML | Plain HTML | Pass | Pass | No |
| Lovable | React + Vite | Pass | Pass* | Workaround |
| Base44 | React 18 + Vite | Pass | Fail | Not supported |
| Bolt (before) | React + Vite | Pass | Fail | Yes |
| Bolt (after) | Astro | Pass | Pass | Rebuilt to Astro |
| v0 | Next.js 16 | Pass | Pass | No |
That is the core finding. Topic recognition was easy. Body retrieval was where the stack differences actually showed up.
Why That Difference Matters
This is where people get fooled. A page can look complete in the browser, expose a solid title and meta description, and still fail when an agent is asked for something that lives in the body. A correct summary is not proof that the agent actually read the page. In this test, metadata success was a weak proxy for real retrieval success.
What the Agents Could Retrieve
1. Title and meta description (topic recognition)
Every implementation exposed a title tag and meta description that the agents could read. This is the easy part. Even CSR apps inject these into the static HTML shell before JavaScript runs.
| Implementation | ChatGPT | Claude |
|---|---|---|
| Static HTML control | Pass | Pass |
| Lovable | Pass | Pass |
| Base44 | Pass | Pass |
| Bolt implementation that returned a CSR shell | Pass | Pass |
| Bolt implementation rebuilt to Astro | Pass | Pass |
| v0 | Pass | Pass |
This matters because it shows that even when body content is not available, page level signals can still carry topic information.
2. Table retrieval from the page body
The second question targeted structured content in the page body. The correct answer was 288.
| Implementation | ChatGPT | Claude |
|---|---|---|
| Static HTML control | Pass | Pass |
| Lovable | Pass* | Pass* |
| Base44 | Fail | Fail |
| Bolt implementation that returned a CSR shell | Fail | Fail |
| Bolt implementation rebuilt to Astro | Pass | Pass |
| v0 | Pass | Pass |
This is where the gap became obvious. The table was visible to a human visitor, but not reliably retrievable across all implementations.
These screenshots are from before Lovable applied its workaround. ChatGPT on the Lovable page. It thought for over a minute, then refused to guess:
The same question on the Bolt Astro version. Five seconds:
3. Paragraph level fact retrieval
The third question targeted a specific statistic buried in paragraph text. The correct answer was r=0.72, n=84.
| Implementation | ChatGPT | Claude |
|---|---|---|
| Static HTML control | Pass | Pass |
| Lovable | Pass* | Pass* |
| Base44 | Fail | Fail |
| Bolt implementation that returned a CSR shell | Fail | Fail |
| Bolt implementation rebuilt to Astro | Pass | Pass |
| v0 | Pass | Pass |
Same pattern. Same content. Same questions. Different retrieval outcome based on what the deployed page returned.
Again, before Lovable’s workaround. ChatGPT searched the Lovable page for “Torvik,” “tower,” “mating,” and “stone.” Zero matches:
On the Bolt Astro page, it quoted the exact line:
What Changed When I Asked the Builders to Fix It
There is an entire ecosystem of prerendering and static generation solutions. That is not what this test is about. The point here is narrower: what could the builders themselves produce when asked to make the content visible without requiring JavaScript? That is where the biggest product differences showed up.
Bolt: passed after rebuilding to Astro
- Test URL: csr-test.bolt.host
- Stack: React + Vite at first, then Astro after the prompt
- Default output: CSR shell. Failed body retrieval.
- When asked to make it SSR: Bolt rebuilt the entire project in Astro. The output changed from a JS rendered SPA to a static site with content baked into the HTML. Both agents passed all three questions after that. This is a real architectural fix. Full disclosure: Astro SSG on Cloudflare Workers is the same stack I use for this site.
Lovable: passed with a workaround
- Test URL: csr-test.lovable.app
- Stack: React + Vite
- Default output: CSR shell. Failed body retrieval.
- When asked to make it SSR: Lovable injected static HTML into the
<div id="root">shell usingnoscript-headerclass names. ChatGPT found the data after this change, but still identified the page as “loading as a client-rendered app” and took over 60 seconds to extract the answer, compared with 5 seconds on Bolt’s Astro version. This is a hardcoded workaround, not a rendering architecture change. It does not scale to dynamic routes, API driven content, or sites with more than a handful of pages. It also creates a real risk of content drift over time, because the content visible to crawlers can diverge from the content rendered by the app.
Base44: failed, no SSR support
- Test URL: csr-test.base44.app
- Stack: React 18 + Vite
- Default output: CSR shell. Failed body retrieval.
- When asked to make it SSR: Base44 told me directly that SSR is not possible on the platform. “Base44 apps are React SPAs. There’s no way to add server side rendering without switching to a different framework, which isn’t supported here.”
v0: passed by default
- Test URL: v0-csr-test.vercel.app
- Stack: Next.js 16 + React 19
- Default output: SSR. Content present in initial HTML response.
- No fix needed. Both agents passed all three questions on the first try.
What the HTML Difference Looked Like
The only thing that mattered was what the deployed page returned before JavaScript ran.
In the weaker cases, the initial response mostly exposed the shell.
<body>
<div id="root"></div>
</body>In the stronger cases, the initial response already contained the heading, paragraph text, and table content.
<body>
<h1>The Veloran Crested Ibex</h1>
<p>...</p>
<table>
<tr><td>2023</td><td>288</td></tr>
</table>
</body>That difference is the mechanical center of the whole article.
What This Test Shows
-
Topic visibility is easier than body visibility.
A page can expose enough signal for an agent to identify the topic while still failing body retrieval. -
A correct summary proves less than people think.
Reading the title and meta description is not the same as reading the page. -
The real product difference is fixability.
What matters is not only what the builder shipped first, but whether it could produce retrieval friendly output when pushed. -
Not all fixes are equal.
Rebuilding to an architecture that returns meaningful HTML is one thing. Injecting hardcoded content into the shell is another.
This is not a trivial engineering problem. I worked on it at Wix for years. It’s expensive. It’s slow. It breaks in ways you don’t expect. But the core rule is simple: if the content is not in the HTML, agents can’t read it.
Whose Problem Is This?
Both sides own a piece of this.
AI builders need to produce output that is readable by default. Not just meta tags for social previews. The actual text. The tables. The data. If a platform generates a website, the HTML should contain the content. That should be table stakes.
I see new companies launching every month to solve this with prerendering layers and SSG conversion services. They work. But the fact that an entire cottage industry exists to patch the output of these builders tells you something about the output itself. It also adds yet another layer to the stack. Another dependency, another bill, another thing that can break silently. I thought the whole point of AI builders was to make things simpler.
But AI companies also need to invest in reading the web as it actually exists. Google understood this years ago. They didn’t build their Web Rendering Service out of kindness. They built it because they realized that to be the internet’s index, you need to be able to read JavaScript-rendered sites. It took them years and enormous infrastructure investment. But they did it because the alternative was an incomplete picture of the web.
OpenAI and Anthropic face the same choice. Right now, their retrieval bots fetch raw HTML and move on. That works for most of the web. But more sites are being built with these tools every month. More empty containers. More invisible content. More gap between what exists and what agents can actually read.
There’s also a third possibility: neither side fixes their current approach, and instead the industry moves toward new ingestion mechanisms entirely. Structured feeds, API-based content delivery, or standards like llms.txt could let AI agents access page content without needing to render HTML at all. That would sidestep the rendering problem completely. We’re not there yet, but it’s worth watching.
In the meantime, both sides have work to do. The builders need to ship readable output. The AI companies need to invest in reading what’s actually out there.
What This Test Does Not Show
A caveat: this was one controlled test, not a universal law. Some CSR pages may still be retrievable in some circumstances. I did not test external prerendering services or measure ranking outcomes. What I did measure was whether the builders themselves could produce readable HTML, and they differed significantly.
Practical Takeaways
If you only need topic recognition, you still have some useful levers even on weaker implementations:
- Use a clear title
- Write a strong meta description
- Use a descriptive URL
That will not guarantee body retrieval, but it improves the signals agents can still see.
If you need real retrievability, the rule is stricter: make sure the important content is present in the initial HTML response. That does not mean every site needs the same stack. It does mean you should know whether your builder can produce retrieval friendly output, or whether you are relying on a workaround.
Two quick ways to check your own site:
- Disable JavaScript in the browser and reload the page. If the important content disappears, that is a bad sign.
- Open a fresh chat in ChatGPT or Claude, give it the URL, and ask for a detail that can only be answered from the page body. Ask for a number, a name, or a buried fact. Not a summary.
That second method is exactly what I used in this test. It takes less than a minute and tells you a lot.
Who Should Care Most
This matters for pages where discoverability matters:
- landing pages
- product pages
- help content
- articles
- branded pages you want agents to understand beyond the title
For internal tools, private dashboards, and back office workflows, this mostly does not matter.
Final Take
The takeaway is not that AI site builders are bad. It’s that fast generation and good retrieval are not the same thing. All of the tested implementations gave agents enough signal to understand the topic, but only some exposed enough HTML for reliable body retrieval. The more useful product difference was not just who passed first, but who could produce retrieval friendly output when pushed, and who left you with a workaround instead of a real solution.

